Building on the concept of the prediction table, the algorithm has been extended with a gap parameter.
Now, the algorithm predicts the most likely byte that comes after the current byte, allowing for a gap between them.
In practice, this means the algorithm can find frequent 16-bit patterns with gaps. The example below shows a gap of 3 bytes between two 00 bytes.
00 +(3) 00The tool FF-16 (Find Frequent 16-bit) utilizes this algorithm.
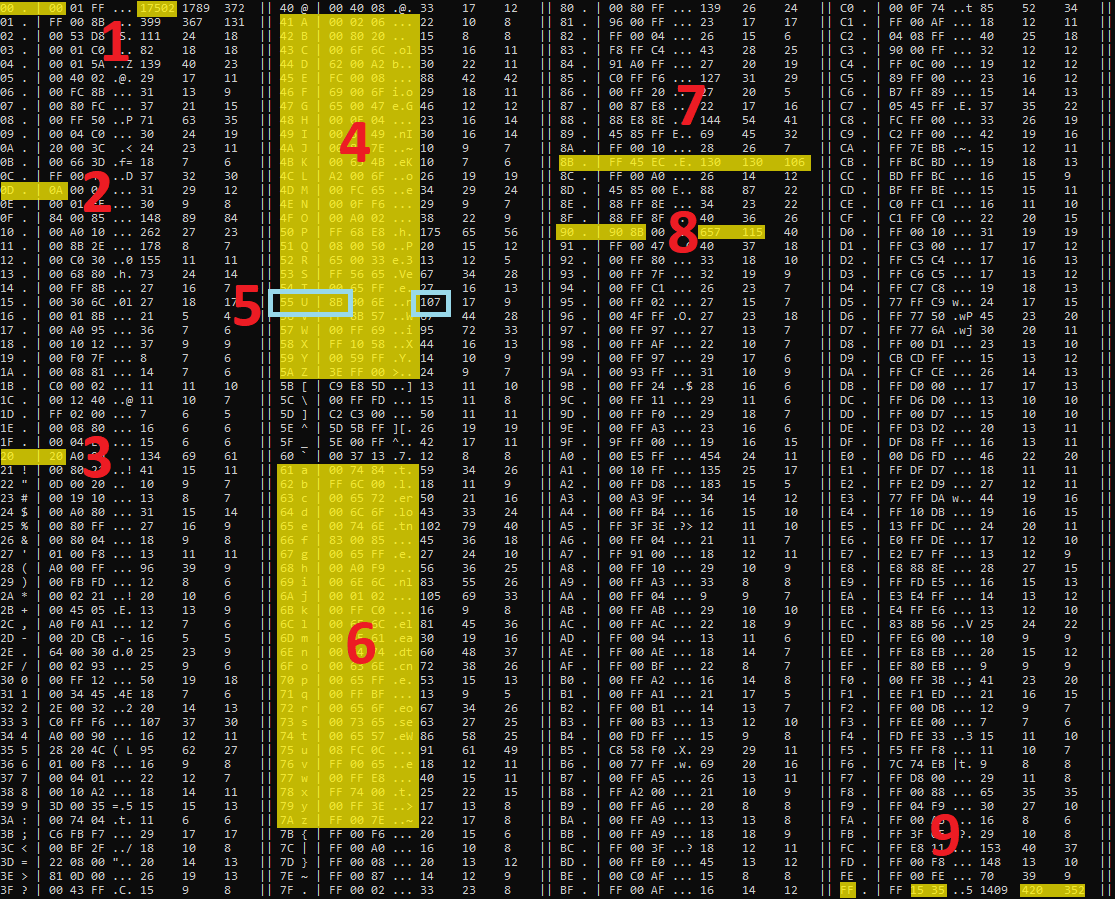
FF-16 processes a file by splitting it into multiple 256-byte blocks, running the algorithm independently on each block. While the analysis occurs at the block level, the results are displayed at the bucket level, where a bucket consists of multiple blocks. This approach ensures that the user is not overwhelmed with excessive detail, making the output more practical to interpret.
Map View
When running FF-16 on notepad.exe the output looks like this.
BucketSize: 2816 0 1 2 3 4 5 6 7 Pattern Ascii Blocks 0123456789ABCDEF0123456789ABCDEF0123456789ABCDEF0123456789ABCDEF0123456789ABCDEF0123456789ABCDEF0123456789ABCDEF01234567 00 00 |..| 542 |*********************************************************** ***** **** ******** ********* * ***| - - 309 | **** ************************* | CC CC |..| 91 | ********* ******** ****** ** * ****** * | 48 8B |H.| 68 | **** *** **** * * * ** **** * * ****** | 00 +(3) 00 |..| 42 | **** * ***** * ** ** | FF +(3) FF |..| 42 | ** *** **** | 00 +(1) 00 |..| 41 | ** * ** ** * * * * | 00 +(7) 00 |..| 40 | *** **** ** ***** * * * | 00 +(11) 00 |..| 17 | * * * ** * | 00 +(15) 00 |..| 17 | * * *** * *** * | 02 00 |..| 15 | ** * ** * ** * * * | 01 00 |..| 12 | * ** * * *** * | FF +(11) FF |..| 12 | ** | 00 +(19) 00 |..| 12 | * * * * | 41 8B |A.| 11 | * ** ** | 48 89 |H.| 10 | ** ** | 48 +(5) 00 |H.| 8 | ** * * * ** | <LIST CUT HERE>
The map lists frequent patterns and marks buckets with * if they contain at least one block with a frequent pattern. The patterns occurring in more blocks are listed first. The map presents an overview of the file layout, showing the dominant patterns in different sections of the file.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}