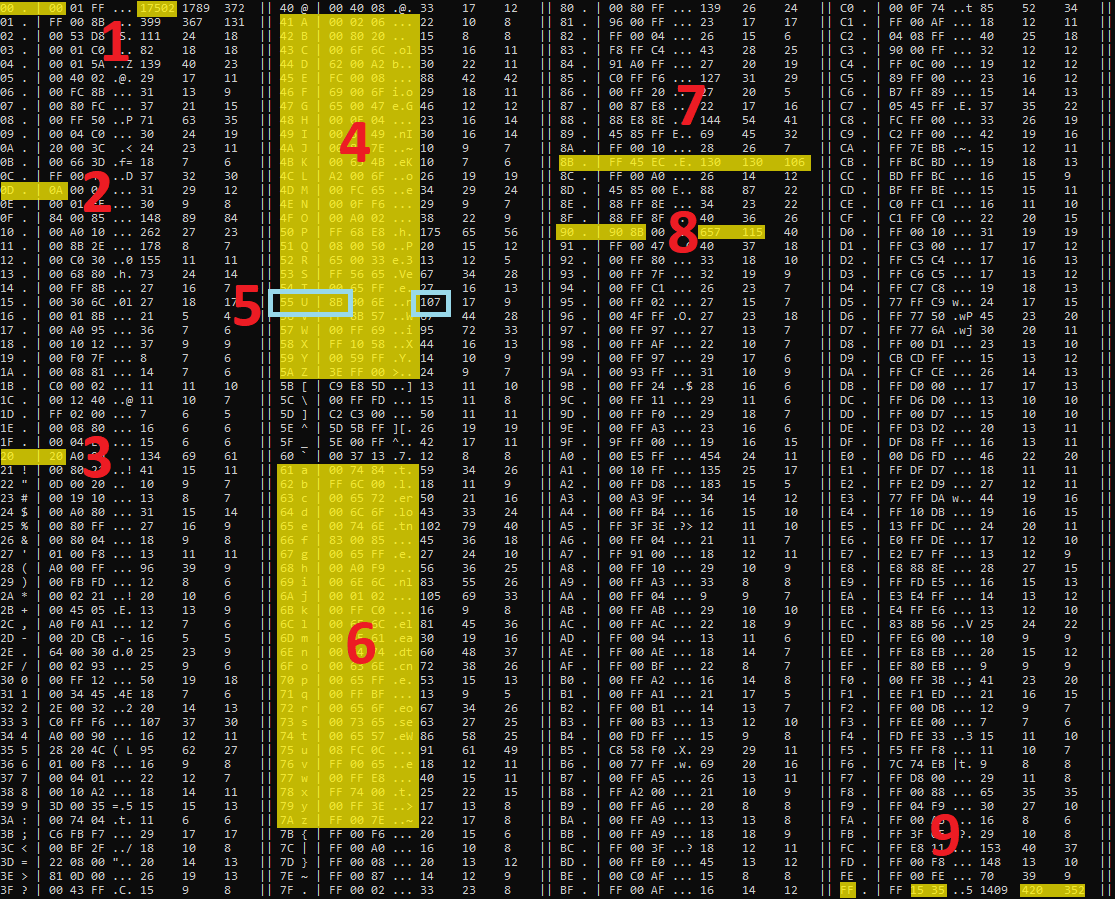
What is this screenshot about?
This is a prediction table which tells what is the most likely (second most likely, third most likely) byte which comes after the current byte.
The prediction table has 4 columns. Each column contains the current byte, the ASCII representation of the current byte, the top three bytes most likely come after the current byte, their ASCII representation, and the number of occurrences of the top three bytes in the context of the current byte.
The current byte ranges from 0 to 255, inclusive.
How the prediction table is useful for static binary analysis?
The biggest usefulness of what the prediction table provides is the reduction of the data while aiming to keep the key redundancies of the input data visible. The prediction table is always fixed in size regardless of the size of the input data, and it fits on a single screen. Therefore, it’s easier to analyze the resulting prediction table and easier to make automation on it.
The generation of the prediction table is a very straightforward and single-pass process, and therefore it’s a pretty fast one. And because of the simplicity, the algorithm is low risk to have errors that would lead to inaccurate output. It is simple to understand if the output is correct.
Redundancies which can intuitively be picked by the human eye when skimming through the data might be seen in the prediction table. Below is an example of how to read the prediction table of notepad.exe.
What can specifically be understood from the prediction table?
The screenshot of the prediction table is annotated by numbers in red.
Number 1
Quite often 00 comes after 00. Specifically, the occurrence of 00 in the context of 00 is 17502 which is the largest occurrence number in the table. It is commonly seen redundancy in EXE files because zeroes are used to fill slack space (to align section boundaries), used in header fields, and in x86 instructions.
Number 2
The most likely byte which comes after 0D is 0A. This sequence indicates a line break of CR LF. This kind of line break can be found in textual data handled by Windows applications. It is common to see that EXE files contain textual data like notepad.exe.
Number 3
Space (20) comes after space, or in other words, runs of spaces. Usually, this pattern is seen when there is indented textual data and for the indentation, spaces are used rather than tabs. In this case, there is an embedded XML-based document with space indentation.
Number 4-6
In most cases, an ASCII printable letter comes after an ASCII printable letter. That indicates the presence of text.
In many cases, 00 comes after ASCII printable letter. That indicates the presence of Unicode text.
Of course, both can be found in notepad.exe.
Number 5
Often, 8B comes after 55.
That’s a part of the sequence 55 8B EC push ebp; mov ebp, esp which is part of the x86 function epilogue and is commonly seen in EXE files.
Number 7
8B is a part of mov instruction which is one of the most often occurring instructions in x86 code in EXE files. And that’s why the top three occurrence numbers in the context of 8B are high compared to the occurrence numbers of many other contexts.
Number 8
These indicate sequences of nop (90) instructions sometimes followed by mov (8B) instructions. Again, note the occurrence number in the context of 90.
Number 9
The sequences FF 15 and FF 35 are parts of call and push instructions commonly found in x86 code in EXE files.
Note
There are other patterns that are not listed here nevertheless can be seen in the prediction table that confirm the presence of x86 code in EXE file. The goal here is to demonstrate that solely, prediction table is useful to make quick decisions on the content of the file.
Are there redundancies that this prediction table doesn’t pick up?
I used the simplest possible implementation of the prediction table generator. It makes sense to start with that.
A prediction table made by an enhanced generator could pick up more interesting patterns and redundancies, for example when the correlated byte is not the following byte to the current byte instead the correlated byte is at an arbitrarily chosen distance from the current byte.